File
named collection (메모리는 주소를 통한 접근)
비휘발성의 보조기억장치에 저장
운영체제는 다양한 저장 장치를 file 이라는 동일한 논리적 단위로 볼 수 있게 해 줌
Operation 종류 : create, read, write, reposition, delete, open, close
File attribute (metadata)
파일 이름, 유형, 저장위치, 파일사이즈, 접근권한, 시간(생성/변경/사용), 소유자과 같은
파일 자체의 내용이 아니라 파일을 관리하기 위한 각종 정보들
File system
운영체제에서 파일을 관리하는 부분
파일 및 파일의 메타데이터, 디렉토리 정보
파일의 저장 방법 결정
파일 보호
Directory
파일의 메타데이터 중 일부를 보관하고 있는 일종의 특별한 파일
그 디렉토리에 속한 파일 이름 및 파일 attribute들
Operation 종류 : search for a file, create a file, delete a file, list a directory, rename a file, traverse the file system
Partition(=Logical Disk)
하나의 물리적 디스크 안에 여러 파티션을 두는게 일반적
여러 개의 물리적인 디스크를 하나의 파티션으로 구성하기도 함
물리적 디스크를 파티션으로 구성한 뒤 각각의 파티션에 file system을 깔거나 swapping 등 다른 용도로 사용 가능
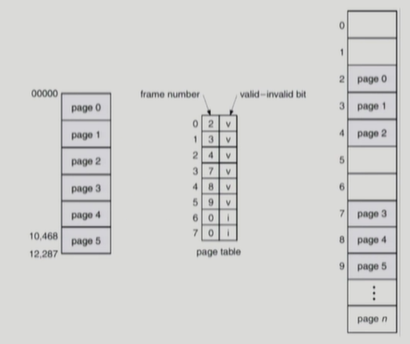
open()
파일의 메타데이터를 메모리로 올린다.
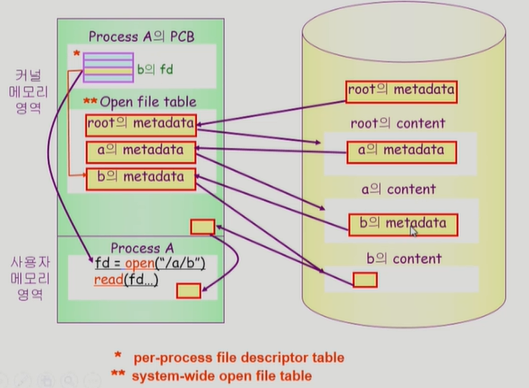
1) fd = open("/a/b") : 프로그램이 b 메타데이터 정보를 요청
2) 시스템콜을 하여 CPU를 운영체제에 넘긴다.
3) CPU가 root 메타데이터를 먼저 메모리에 올린다(root 메타데이터의 디렉토리는 이미 알고 있음)
4) root 메타데이터를 연다
5) root 메타데이터에 존재하는 a 메타데이터의 파일시스템상 위치정보로 디스크에서 a의 메타데이터를 가져와 메모리에 올린다
6) a의 메타데이터를 연다
7) a의 메타데이터에 존재하는 a content의 파일시스템상 위치정보로 디스크에서 a의 content 안에 존재하는 b의 메타정보를 가져와 메모리에 올린다
8) b의 메타정보를 가리키는 포인터의 인덱스(파일 디스크립터) 값을 리턴
9) read(fd...) : 프로그램이 b content 정보 요청(읽기)
10) 읽은 내용을 사용자 프로그램(Process A)에 직접 주는게 아닌, 커널 메모리 영역(buffer cache)으로 가져온다
11) 사용자 메모리영역(Process A)엔 그 내용을 카피해서 준다.
※ 만약 다른 프로그램(Process B)에서 b의 content 를 요청한다면 운영체제가 buffer cache에서 전달해준다
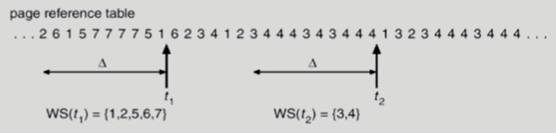
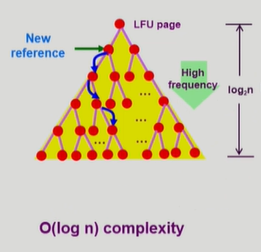
※ File System 의 Buffer cache 환경에선 운영체제가 모든 정보를 알고 있으므로(파일 시스템 접근시 시스템 콜을 통해 제어권이 CPU로 넘어오므로) LRU, LFU 알고리즘을 사용할 수 있다.
※ per-process file descriptor table : 파일 디스크립터 테이블은 프로세스마다 따로 존재
※ system-wide open file table : system wide 로 전체 시스템에 한개로 관리되지만 각각의 프로그램들이 파일의 offset을 프로그램 별로 관리하기 위한 공간(table)은 따로 존재
File Protection
1. Access control matrix : linked list 형태로 권한 관리 (overhead가 큼)
Access control list : 파일별로 누구에게 어떤 접근 권한이 있는지 표시
Capability list: 사용자별 자신이 접근 권한을 가진 파일 및 해당 권한 표시
2. Grouping
전체 user를 owner, group, public의 세그룹으로 구분
각 파일에 대해 세그룹의 접근 권한(rwx)을 3비트씩 표시
UNIX를 포함한 대부분의 OS에서 사용

3. Password
파일마다 password를 두는 방법
rwx 마다 password를 하나씩 부여해야하므로 관리가 어려움
File System의 Mounting
파티션을 통해 여러개의 논리적 디스크로 분리된 하나의 물리적 디스크
각각의 논리적 디스크에 file system 존재
다른 파일시스템에 접근할 경우 mount 사용

disk3의 루트를 disk1의 usr 경로에 연결(mount)하여 타 파일시스템 접근이 가능
※ 이화여대 반효경 교수님의 운영체제 강의 정리