Allocation of File Data in Disk
Contiguous Allocation

단점 :
- external fragmentation, hole이 발생
장점 :
- Fast I/O (헤드가 이동하는 시간이 짧음)
- 한번의 seek/rotation 으로 많은 바이트 transfer
- Realtime file용, process의 swapping 용으로 사용
- Direct access(=random access) 가능
Linked Allocation

장점 :
- external fragmentation 발생 없음
단점 :
- No random access
- Reliability 문제
- 한 sector 가 고장나 pointer 유실시 많은 부분을 잃음
- Pointer를 위한 공간이 block의 일부가 되어 공간 효율성을 떨어뜨림 (512bytes는 sector로, 4bytes는 pointer로 사용됨)
* FAT(File-allocation table) 파일 시스템 : 포인터를 별도의 위치에 보관하여 reliability와 공간효율성 문제 해결
Indexed Allocation

장점 :
- external fragmentation 발생 없음
- Direct access 가능
단점 :
- Small file의 경우 공간 낭비
- 파일이 너무 큰 경우 하나의 block 으로 index 를 저장 할 수 없음
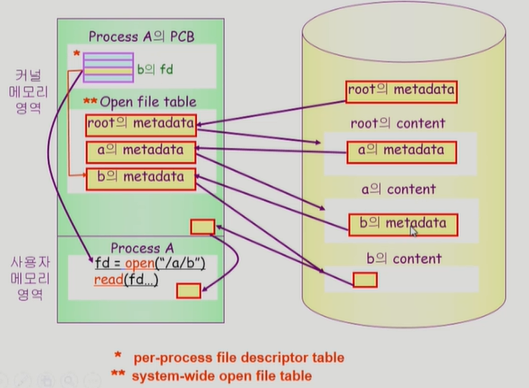
UNIX 파일시스템 구조

Boot block
- 모든 파일시스템은 boot block 이 제일 위에있음
- 컴퓨터 부팅시 0번블럭(붙 블럭)을 올려서 부팅시킴
Superblock
- 파일시스템에 관한 총체적인 정보를 담고 있다
Inode
- 파일 이름을 제외한 파일의 모든 메타 데이터 저장
Data block
- 파일 실제 내용 보관
FAT 파일 시스템

FAT
메타데이터의 일부를 보관 (위치정보)
FAT 배열의 크기는 data block 의 크기와 동일
FAT 은 복제본을 저장하여 신뢰도를 높임
Free Space Management : 비어있는 블락 관리방법
1. Bit map

Bit map 을 위한 부가적인 공간을 필요로 함
연속적인 n개의 free block을 찾는데 효과적
2. Linked list
모든 free block들을 링크로 연결(free list)
연속적인 가용공간을 찾는게 힘듦
공간낭비 없음
3. Grouping
linked list 방법의 변형
첫번째 free block이 n개의 pointer를 가짐
n-1 pointer는 free data block을 가리킴
마지막 pointer가 가리키는 block은 또 다시 n pointer를 가짐
4. Counting
프로그램들이 종종 여러 개의 연속적인 block을 할당하고 반납한다는 성질에 착안
Directory Implementation : 디렉토리 저장 방법
1. Linear list
- <filename, file의 메타데이터>의 list
- 구현이 간단함
- 디렉토리 내에 파일이 있는지 찾기 위해서는 linear search 필요(time-consuming)

2. Hash Table
- linear list + hashing
- Hash table은 file name을 이 파일의 linear list의 위치로 바꾸어줌
- search time을 없앰
- Collision 발생 가능

* F에 Hash 함수 적용시 F는 특정 범위로 한정지어짐.
* Hash 함수를 적용하여 조회
※ 이화여대 반효경 교수님의 운영체제 강의 정리