[Process Synchronization]
공유 데이터(shared data)의 동시 접근(concurrent acecss)은 데이터의 불일치 문제(inconsistency)를 발생시킬 수 있다
일관성(consistency)를 위해 협력프로세스간의 실행순서를 정해주는 메커니즘이 필요
[Race condition]
여러 프로세스들이 동시에 공유데이터를 접근하는 상황
데이터의 최종 연산 결과는 마지막에 그 데이터를 다룬 프로세스에 따라 달라진다
=> race condition을 막기 위해 concurrent process는 동기화(synchronize) 되어야 한다
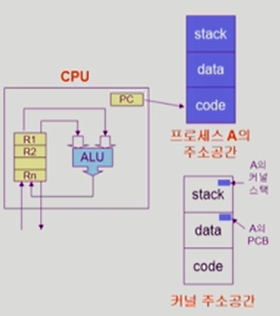
Process 가 한 개 있는 경우
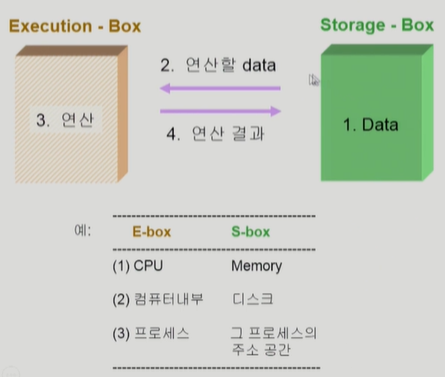
Process가 두 개 있는 경우
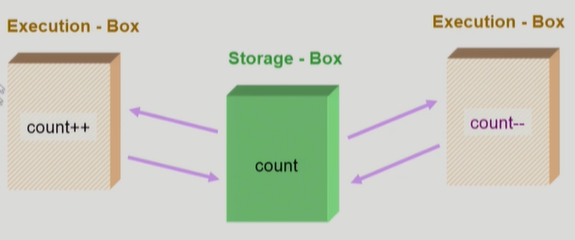
S-box(memory address space)를 공유하는 E-box(CPU process)가 여럿 있는 경우,
Race Condition의 가능성이 있다
[OS에서 race condition이 발생하는 경우]
1) interrupt handler v.s. kernel
커널모드 running 중 interrupt가 발생하여 인터럽트 처리루틴이 수행
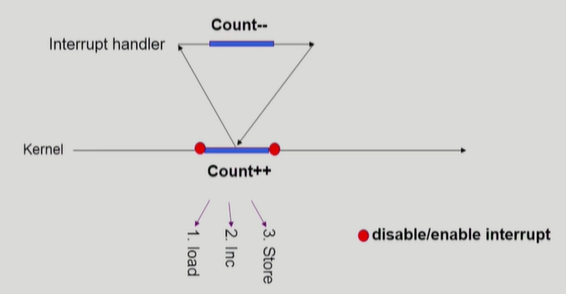
커널모드 running 중 interrupt 가 발생하여 인터럽트 처리루틴이 수행
해결책 : 처리가 완료되기 전까지 interrupt를 받아주지 않는다
2) preempt a process running in kernel

해결책 : 커널모드에서 수행 중일 때는 CPU를 preempt(선점) 하지 않음. 커널 모드에서 사용자 모드로 돌아갈 때 preempt
3) multiprocessor

multiprocessor의 경우 위의 케이스들과 달리 interrupt enable/disable로 해결되지 않는다.
해결책 1) 한번에 하나의 CPU만이 커널에 들어갈 수 있게 하는 방법
해결책 2) 커널 내부에 있는 각 공유데이터에 접근할 때마다 그 데이터에 대한 lock/unlock을 하는 방법
The Critical-Section problem : 임계영역 문제
n개의 프로세스가 공유 데이터를 동시에 사용하기를 원하는 경우
각 프로세스의 code segment에는 공유 데이터를 접근하는 코드인 critical section이 존재
problem : 하나의 프로세스가 critical section에 있을 때 다른 모든 프로세스는 critical section에 들어갈 수 없어야 한다
프로그램적 해결법의 충족 조건
1) Mutual Exclusion (상호배제)
프로세스가 critical section 부분을 수행 중이면 다른 모든 프로세스들은 그들의 critical section에 들어가면 안된다
2) Progress
아무도 critical section에 있지 않은 상태에서 critical section에 들어가고자 하는 프로세스가 있으면 critical section에 들어가게 해주어야 한다
3) Bounded Waiting(유한한 대기)
프로세스가 ciritical section에 들어가려고 요청한 후부터 그 요청이 허용될 때까지 다른 프로세스들이 critical section에 들어가는 횟수에 한계가 있어야 한다(starvation 방지)
[Critical Section problem 해결 알고리즘 1]
Process0 이 한 번 수행으로 끝이난 경우 Process1 은 다시 들어갈 수 없음
(타 프로세스가 turn 을 내 값으로 바꿔줘야만 내가 들어갈 수 있기 때문) : 과잉양보 발생
-> mutual exclusion 은 만족하나 progress 는 만족하지 않음
Process0]
do {
while(turn != 0); // my turn?
critical section
turn = 1;
remainder section // now it's your turn
} while(1)
Process1]
do {
while(turn != 1); // my turn?
critical section
turn = 0;
remainder section // now it's your turn
} while(1)
[Critical Section problem 해결 알고리즘 2]
두 프로세스가 2행까지(while문) 수행 후 끊임 없이 양보하는 상황 발생 가능
(critical section 진입 후 flag를 false 로 두어 나왔음을 알리지만 2행까지 실행된 경우 두 프로세스가 loop가 돌며 계속 양보하게 되므로)
Process0, Process1]
do {
flag[i] = true; //pretend I am in
while(flag[j]); //is he also in? then wait
critical section
flag[i] = false; // i am out now
remainder section
} while(1);
[Critical Section problem 해결 알고리즘 3]
Peterson's Algorithm
Mutual Exclusion, Progress, Bounded waiting 을 모두 만족
하지만 Busy waiting(=spin lock=loop) : CPU , memory 를 계속 사용하며 wait
Process0]
do {
flag[0] = true; //My intention is to enter
turn = 1; // set to his turn
while(flag[1] && turn == 1); // wait only if
critical section
flag[0] = false;
remainder section
} while(1);
Process1]
do {
flag[1] = true; //My intention is to enter
turn = 0; // set to his turn
while(flag[0] && turn == 0); // wait only if
critical section
flag[1] = false;
remainder section
} while(1);
하드웨어적으로 Test와 Modify를 atomic 하게(읽기와 쓰기를 한번에(하나의 instruction으로)) 수행할 수 있도록 지원하는 경우 앞의 문제는 간단히 해결
: interrupt 등으로 프로세스가 CPU를 뺏길 때, 실행 하던 instruction은 끝마치고(라인 한 줄) 뺏긴다.
instruction 을 한 줄이 아닌 두개의 instruction 으로 지원하여 instruction+flag처리를 한 번에 다룰 경우, 임계영역에 대한 처리가 간단해진다
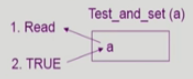
Synchronization variable :
boolean lock = false;
do {
while(Test_and_Set(lock));
critical section
lock = false;
remainder section
}
※ 이화여대 반효경 교수님의 운영체제 강의 정리
'Computer Science > OS' 카테고리의 다른 글
| [OS] 운영체제 7. Process Synchronization 3 : 동기화 문제의 예, 모니터 (0) | 2020.02.08 |
|---|---|
| [OS] 운영체제 7. Process Synchronization 2 : 세마포어(semaphore) (0) | 2020.02.06 |
| [OS] 운영체제 6. CPU Scheduling : CPU 성능척도, 스케쥴링 방법(FCFS, SJF, Priority Scheduling, Round Robin) (0) | 2020.02.04 |
| [OS] 운영체제 5. Process Management : 프로세스 생성/종료 (0) | 2020.02.01 |
| [OS] 운영체제 4. Thread : 스레드 정의, 효과 및 장점 (0) | 2020.01.27 |