1. We want to create a mobile application with the following requirements
2. Expose as REST API with HTTPS
3. Serverless architecture
4. Users should be able to directly interact with their own folder in S3
5. Users should authenticate through a managed serverless service
6. The users can write and read to-dos, but they mostly read them
7. The database should scale, and have some high read throughput
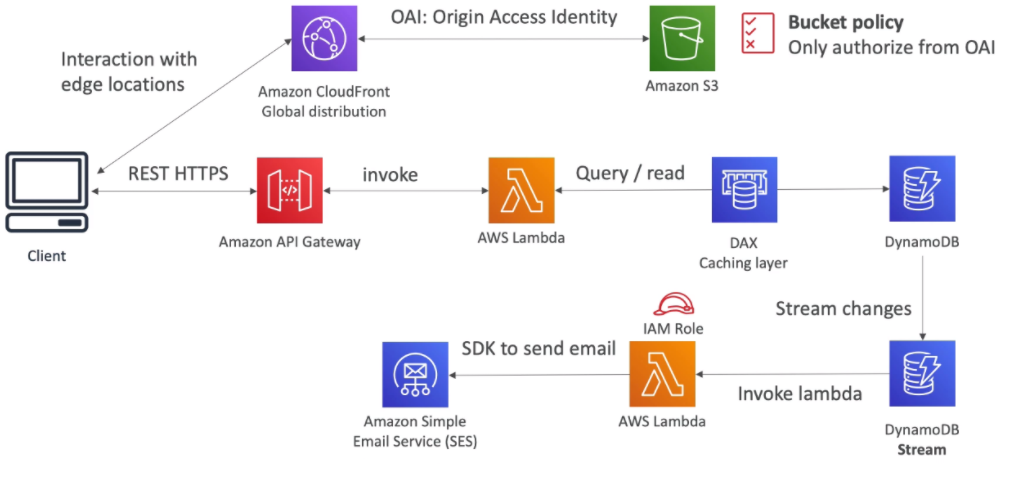
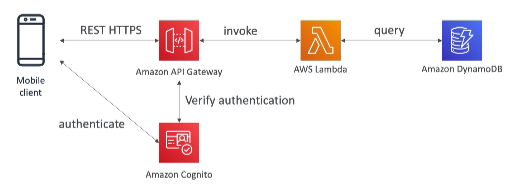
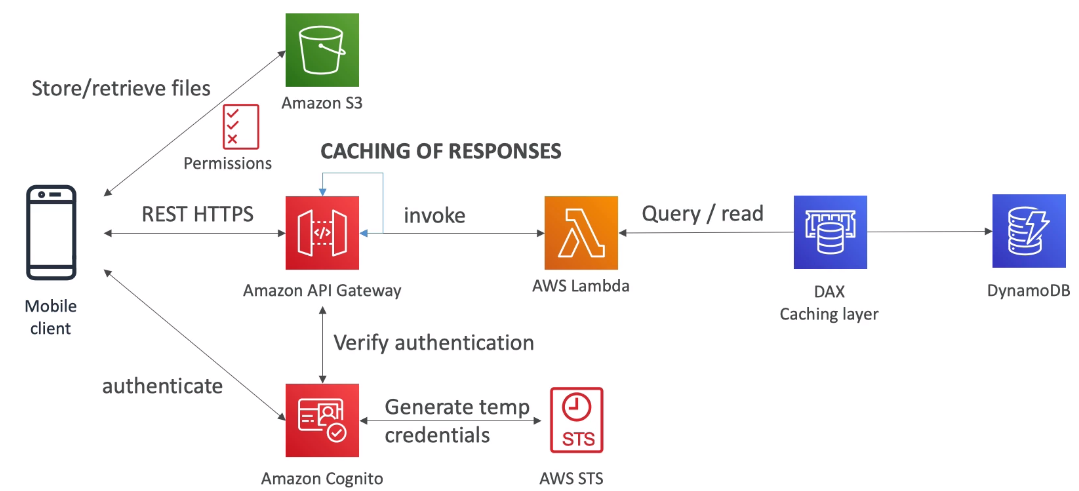
[ 1. Mobile App : REST API layer ]
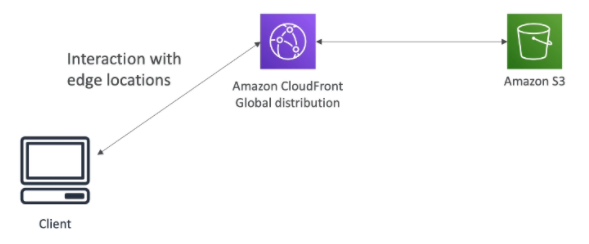
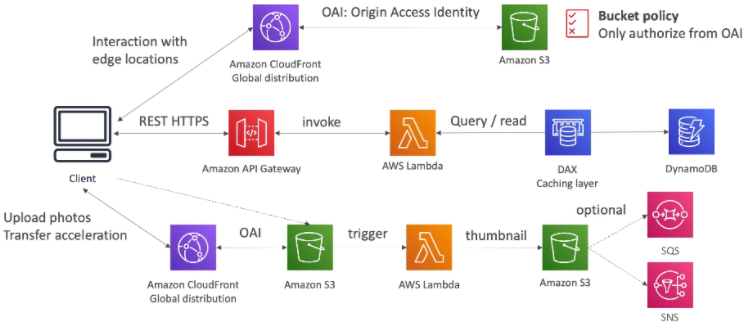
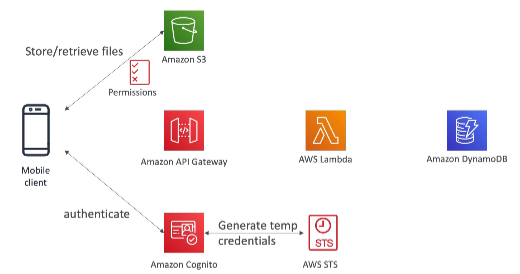
[ 2. Mobile App : giving users access to S3 ]
※ Note : save credentials on S3 (not on your mobile client)
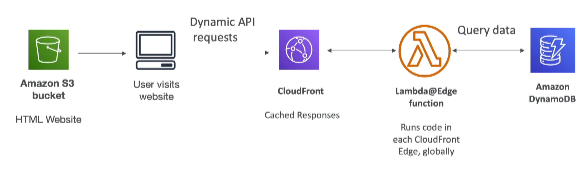
[ 3. Mobile app : high read throughput, static data ]
- Serverless REST API : HTTPS, API Gateway, Lambda, DynamoDB
- Using Cognito to generate temporary credentials with STS to access S3 bucket with restricted policy. App users can directly access AWS resources this way. Pattern can be applied to DynamoDB, Lambda
- Caching the reads on DynamoDB using DAX
- Caching the REST requests at the API Gateway level
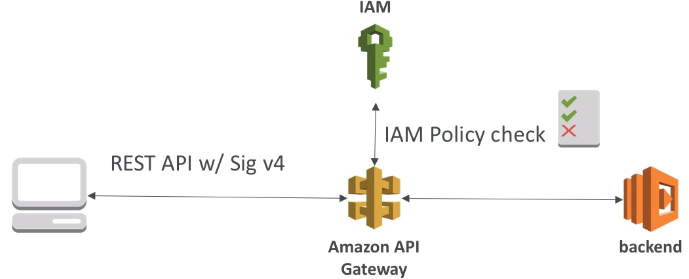
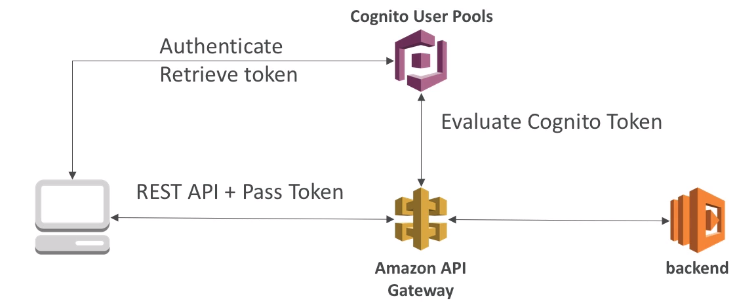
- Security for authentication and authrization with Cognito, STS