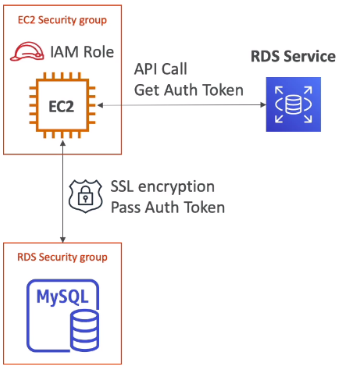
[ S3 Security ]
1) User based
- IAM policies - which API calls should be allowed for a specific user from IAM console
2) Resource Based
- Bucket Policies - bucket wide rules from the S3 console - allows cross account
- Object Access Control List (ACL) - finer grain
- Bucket Access Control List (ACL) - less common
* an IAM principal can access an S3 object if the user IAM permissions allow it OR the resource policy ALLOWS it
* AND there's no explicit DENY
[ S3 Bucket Policies ]
- JSON based policies
Resources : buckets and objects
Actions : Set of API to Allow or Deny
Effect : Allow / Deny
Principal : The account or user to apply the policy to
- Use S3 bucket for policy to :
Grant public access to the bucket
Force objects to be encrypted at upload
[ # Hands-on : Bucket Policies ]
Policy generator 사용
1) Policy Type 선택 : S3 Bucket Policy
2) Add statements
첫번째 statement 설정
Effect : Deny선택
Principal : * (anywhere)
Actions : Put Objects 선택
Amazon Resource Name (ARN) : ARN/* 입력 (S3 management console 에서 ARN(bucket name) 확인 가능)
3) Add Conditions
Condition : Null
Key : s3:x-amz-server-side-encryption
value : true
2) Add statements
두번째 statement 설정
Effect : Deny선택
Principal : * (anywhere)
Actions : Put Objects 선택
Amazon Resource Name (ARN) : ARN/* 입력 (S3 management console 에서 ARN(bucket name) 확인 가능)
3) Add Conditions
Condition : StringNotEquals
Key : s3:x-amz-server-side-encryption
value : AES256
4) Generate Policy 클릭시 JSON 생성됨
5) JSON copy&paste to Bucket policy
* 위와같이 설정시 Object (file) 을 Encryption 설정(SSE-S3) 없이 업로드 할 경우, Access Denied 로 업로드 실패.
Policy generator 사용
1) Policy Type 선택 : S3 Bucket Policy
2) Add statements
첫번째 statement 설정
Effect : Deny선택
Principal : * (anywhere)
Actions : Put Objects 선택
Amazon Resource Name (ARN) : ARN/* 입력 (S3 management console 에서 ARN(bucket name) 확인 가능)
3) Add Conditions
Condition : Null
Key : s3:x-amz-server-side-encryption
value : true
2) Add statements
두번째 statement 설정
Effect : Deny선택
Principal : * (anywhere)
Actions : Put Objects 선택
Amazon Resource Name (ARN) : ARN/* 입력 (S3 management console 에서 ARN(bucket name) 확인 가능)
3) Add Conditions
Condition : StringNotEquals
Key : s3:x-amz-server-side-encryption
value : AES256
4) Generate Policy 클릭시 JSON 생성됨
5) JSON copy&paste to Bucket policy
* 위와같이 설정시 Object (file) 을 Encryption 설정(SSE-S3) 없이 업로드 할 경우, Access Denied 로 업로드 실패.
[ Bucket settings for Block Public Access ]
- Block public access to buckets and objects granted through
1) new access control lists (ACLs)
2) any access control lists (ACLs)
3) new public bucket or access point policies
account settings for Block Public Access 설정/Block public access 설정을 통해 모든 public의 bucket 접근 차단 가능
- Block public and cross-account access to buckets and objects through any public bucket or access point policies
* These settings were created to prevent company data leaks
- If you know your bucket should never be public, leave these on
- Can be set at the account level
[ S3 Security - Other ]
1) Networking :
- Supports VPC Endpoints (for instances in VPC without www internet)
2) Logging and Audit :
- S3 Access Logs can be stored in other S3 bucket
- API calls can be logged in AWS CloudTrail
3) User Security :
- MFA Delete : MFA (multi factor authentication) can be required in versioned buckets to delete objects
- Pre-Signed URLs : URLs that are valid only for a limited time (ex: premium video service for logged in users)
'infra & cloud > AWS' 카테고리의 다른 글
| [AWS] 8. AWS CLI : configuration (0) | 2021.04.01 |
|---|---|
| [AWS] 7-3. S3 Websites : CORS, Eventual Consistency, Strong Consistency (0) | 2021.04.01 |
| [AWS] 7-1. Amazon S3, S3 Encryption (0) | 2021.03.29 |
| [AWS] 6. Beanstalk (0) | 2021.03.29 |
| [AWS] 5-1. Route 53 (0) | 2021.03.24 |