[ Databases in AWS : Redshift ]
PostgreSQL 기반이지만 OLTP(트랜잭션 프로세싱) 지원하지않음
로우기반이아닌 칼럼기반 데이터 저장
MPP(대규모 병렬 쿼리)를 사용하여 다른 데이터베이스에 비해 월등히 뛰어난 성능
AWS Quicksight/Tableau 등의 BI(Business Intelligence) 툴 제공
- Redshift is based on PostgreSQL, but it's not used for OLTP(Online Transaction Processing)
- It's OLAP(Online Analytical Processing) - online analytical processing (analytics and data warehousing)
- 10x better performance than other data warehouses, scale to PBs of data
- Columnar storage of data (instead of row based)
- Massively Parallel Query Execution (MPP) -> reason why it is such high performance
- Pay as you go based on the instances provisioned
- Has a SQL interface for performing the queries
- BI(Business Intelligence tools such as AWS Quicksight or Tableau integrate with it
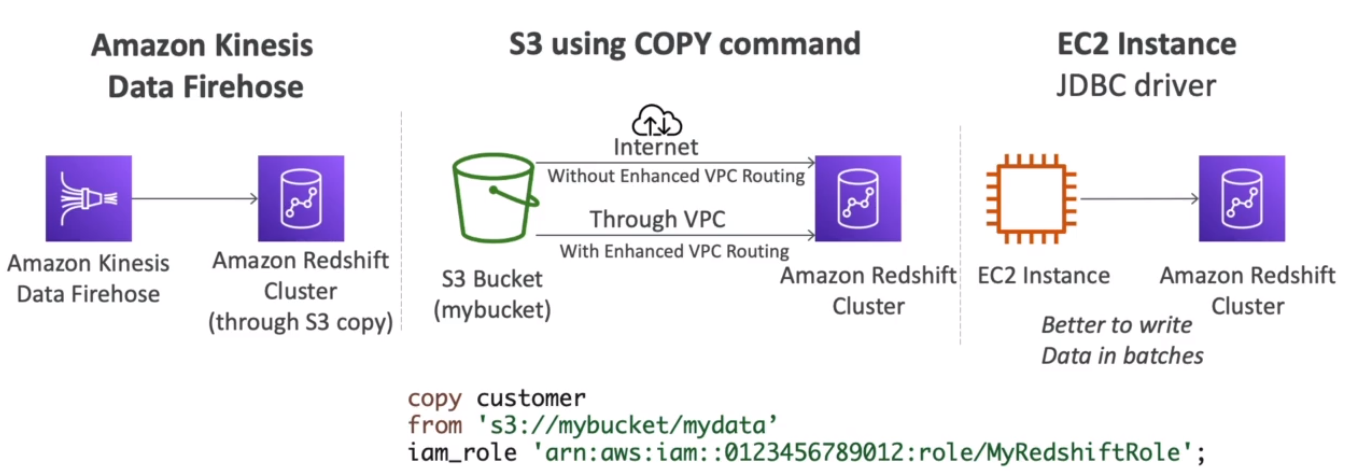
- Data is loaded from S3, DynamoDB, DMS, other DBs
- From 1 node to 128 nodes, upto 128TB of space per node
-- Leader node : for query planning, results aggregation
-- Compute node : for performing the queries, send results to leader
- Redshift Spectrum : perform queries directly against S3 (no deed to load)
- Backup & Restore, Security VPC / IAM / KMS, Monitoring
- Redshift Enhanced VPC Routing : COPY / UNLOAD goes through VPC
[ Redshift - Snapshots & DR ]
- Redshift has no "Multi-AZ" mode
- Snapshots are point-in-time backups of a clust, stored internally in S3
- Snapshots are incremental (only what has changed is saved)
- You can restore a snapshot into a new cluster
-- Automated : every 8 hours, every 5 GB, or on a schedule, Set retention
-- Manual : snapshot is retained until you delete it
- You can figure Amazon Redshift to automatically copy snapshots (automated or manual) of a cluster to another AWS Region
DR(Disaster Recovery) plan : 스냅샷 자동생성 활성화, Redshift cluster 가 자동으로 스냅샷을 다른 AWS Region에 카피하도록 설정

[ Loading data into Redshift ]
[ Redshift Spectrum ]
S3 의 데이터를 Redshift 테이블에 직접 넣지 않고(로딩하지 않고) 쿼리의 실행이 가능하도록 하는 기능
Redshift cluster 가 활성화 되어있어야 사용가능
- Query data that is already in S3 without loading it
- Must have a Redshift cluster available to start the query
- The query is then submitted to thousands of Redshift Spectrum nodes

[ Redshift for Solutions Architect ]
Operations : like RDS
Security : IAM, VPC, KMS, SSL (like RDS)
Reliability : auto healing features, cross-region snapshot copy
Performance : 10x performance vs other data warehousing, compression
Cost : pay per node provisioned, 1/10th of the cost vs other warehouses
vs Athena : faster queries / joins / aggregations thanks to indexes
※ Redshift = Analytics / BI / Data Warehouse
'infra & cloud > AWS' 카테고리의 다른 글
| [AWS] 18-9. Databases in AWS : Neptune (0) | 2021.09.26 |
|---|---|
| [AWS] 18-8. Databases in AWS : Glue (0) | 2021.09.26 |
| [AWS] 18-6. Databases in AWS : Athena (0) | 2021.09.25 |
| [AWS] Databases in AWS : S3 (0) | 2021.09.25 |
| [AWS] 18-5. Databases in AWS : DynamoDB (0) | 2021.09.25 |