* apply: 전달 받은 수신 객체를 변경하여 반환할 때 사용/ 전달받은 수신 객체 반환 * also: 전달 받은 수신 객체를 변경하지 않고 사용할 때 사용(데이터의 유효성 검사할때 유용함)/ 전달 받은 수신 객체 반환 * let: Nullable 수신 받은 객체가 널이 아닌경우 수행 * with: non-nullable(null이 될수 없는) 객체이고 결과가 필요 없는 경우에만 사용 * run: 어떤 값을 계산할 필요가 있거나, 지역 변수를 제한하려 할때 사용
서킷브레이커 패턴이란 외부 서비스에 의한 문제를 방지하기 위해 등장한 디자인 패턴으로 문제가 발생한 지점을 감지하고 실패하는 요청을 계속하지 않도록 방지합니다. 그리고 이를 통해 시스템의 장애 확산을 막고 장애 복구를 도와주며 유저는 불필요하게 대기하지 않게 됩니다. 가정집에 있는 누전차단기가 화재를 막는 것과 비슷하게 CircuitBreaker(직역하면 회로차단기)는 서비스의 장애 전파를 막는다고 이해하면 됩니다.
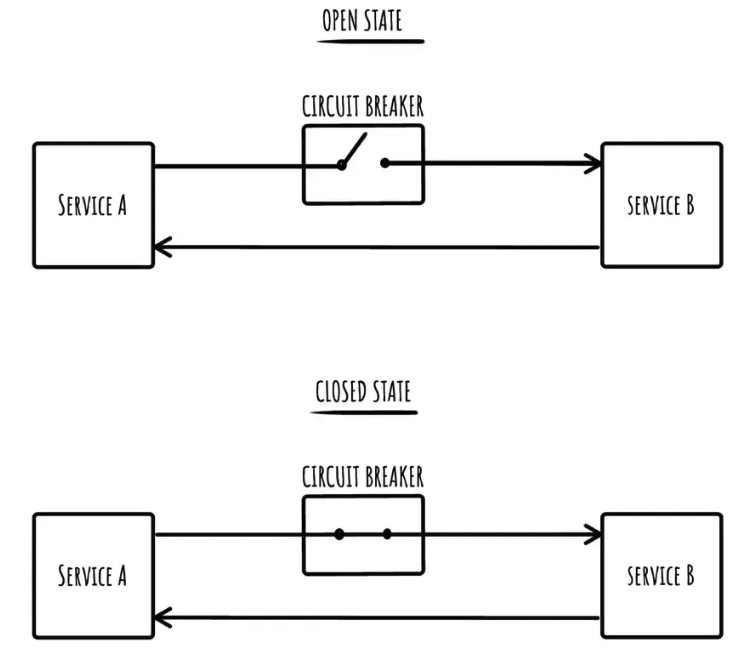
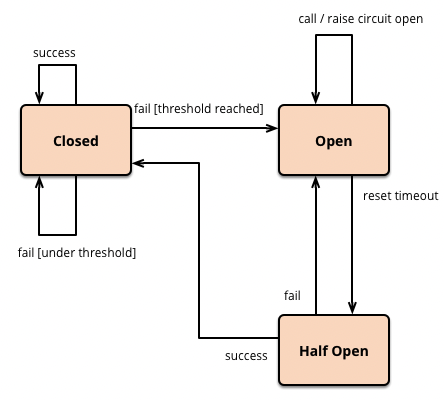
아래 그림과 같이 ServiceA가 ServiceB를 호출 할 때 ServiceB가 반복적으로 실패한다면 CircuitBreaker 를 Open 하여 ServiceB에 대한 흐름을 차단하는게 서킷브레이커의 역할입니다. * CircuitBreaker 의 Open 은 흐름을 차단하는 것으로, 흐름을 열어둔다(opened) 라는 의미가 아닙니다. *반대로 CircuitBreaker 의 Closed 상태는 흐름을 허용하는 정상상태를 의미합니다.
이를 알아보기 위해 resilience4j jar의 CircuitBreakerConfigurationProperties, RetryConfigurationProperties 클래스 내부를 살펴보면,
CircuitBreaker 와 Retry 의 Order 값이 각각 -3, -4 로
별도 처리가 없을 경우 CircuitBreaker 가 Retry 보다 우선으로 적용됨을 알 수 있습니다.
CircuitBreakerConfigurationProperties
public class CircuitBreakerConfigurationProperties extends
io.github.resilience4j.common.circuitbreaker.configuration.CircuitBreakerConfigurationProperties {
private int circuitBreakerAspectOrder = Ordered.LOWEST_PRECEDENCE - 3;
...
}
RetryConfigurationProperties
public class RetryConfigurationProperties extends
io.github.resilience4j.common.retry.configuration.RetryConfigurationProperties {
private int retryAspectOrder = Ordered.LOWEST_PRECEDENCE - 4;
...
}
CircuitBreakerAspect
@Aspect
public class CircuitBreakerAspect implements Ordered {
...
@Override
public int getOrder() {
return circuitBreakerProperties.getCircuitBreakerAspectOrder();
}
}
AOP 기반하에 동작하므로 우선순위를 바꿔서 적용하고자 할 경우 annotation 방식을 사용하여 layer 를 분리하거나 aspectOrder 속성값을 수정하여 적용할 수 있습니다.
Resilience4j Configuration
Resilience4j 의 Configuration 은 yml 파일을 사용하거나, java 코드를 통해 설정할 수 있습니다.
@Configuration
class CircuitBreakerProvider(
val circuitBreakerRegistry: CircuitBreakerRegistry,
) {
companion object {
const val CIRCUIT_MEMDB: String = "CB_MEMDB"
}
@Bean
fun memDBCircuitBreaker(): CircuitBreaker {
return circuitBreakerRegistry.circuitBreaker(
CIRCUIT_MEMDB, CircuitBreakerConfig.custom()
.failureRateThreshold(10F) // 실패비율 10% 이상시 서킷 오픈
.slowCallDurationThreshold(Duration.ofMillis(500)) // 500ms 이상 소요시 실패로 간주
.slowCallRateThreshold(10F) // slowCallDurationThreshold 초과 비율이 10% 이상시 서킷 오픈
.waitDurationInOpenState(Duration.ofMillis(60000)) // OPEN -> HALF-OPEN 전환 전 기다리는 시간
.minimumNumberOfCalls(5) // 집계에 필요한 최소 호출 수
.slidingWindowSize(5) // 서킷 CLOSE 상태에서 5회 호출 도달시 failureRateThreshold 실패비율 계산
.slidingWindowType(CircuitBreakerConfig.SlidingWindowType.COUNT_BASED) // 호출 횟수 기준 계산 (TIME_BASED는 시간 기준)
.ignoreExceptions(StockManageException::class.java) // 화이트리스트로 서킷 오픈 기준 ex 관리
.build()
)
}
"Resilience4j 모듈 중 가장 많이 사용되는 CircuitBreaker, Retry 모듈의 속성값에 대해 간단히 알아보겠습니다."
Resilience4j CircuitBreaker Property
property설명
failureRateThreshold
실패비율 임계치를 백분율로 설정 해당 값을 넘어갈 시 Circuit Breaker 는 Open상태로 전환되며, 이때부터 호출을 차단한다 (기본값: 50)
slowCallRateThreshold
임계값을 백분율로 설정, CircuitBreaker는 호출에 걸리는 시간이 slowCallDurationThreshold보다 길면 느린 호출로 간주, 해당 값을 넘어갈 시 Circuit Breaker 는 Open상태로 전환되며, 이때부터 호출을 차단한다 (기본값: 100)
slowCallDurationThreshold
호출에 소요되는 시간이 설정한 임계치보다 길면 느린 호출로 계산한다. -> 응답시간이 느린것으로 판단할 기준 시간 (60초, 1000 ms = 1 sec) (기본값: 60000[ms])
permittedNumberOfCallsInHalfOpenState
HALF_OPEN 상태일 때, OPEN/CLOSE 여부를 판단하기 위해 허용할 호출 횟수를 설정 수 (기본값: 10)
maxWaitDurationInHalfOpenState
HALF_OPEN 상태로 있을 수 있는 최대 시간이다. 0일 때 허용 횟수 만큼 호출을 모두 완료할 때까지 HALF_OEPN 상태로 무한정 기다린다. (기본값: 0)
slidingWindowType
sliding window 타입을 결정한다. COUNT_BASED인 경우 slidingWindowSize만큼의 마지막 call들이 기록되고 집계됩니다. TIME_BASED인 경우 마지막 slidingWindowSize초 동안의 call들이 기록되고 집계됩니다. (기본값: COUNT_BASED)
slidingWindowSize
CLOSED 상태에서 집계되는 슬라이딩 윈도우 크기를 설정한다. (기본값: 100)
minimumNumberOfCalls
minimumNumberOfCalls 이상의 요청이 있을 때부터 faiure/slowCall rate를 계산한다. 예를들어, 해당값이 10이라면 최소한 호출을 10번을 기록해야 실패 비율을 계산할 수 있다. 기록한 호출 횟수가 9번뿐이라면 9번 모두 실패했더라도 circuitbreaker는 열리지 않는다. (기본값: 100)
waitDurationInOpenState
OPEN에서 HALF_OPEN 상태로 전환하기 전 기다리는 시간 (60초, 1000 ms = 1 sec) (기본값: 60000[ms])
recordExceptions
실패로 기록할 Exception 리스트 (기본값: empty)
ignoreExceptions
실패나 성공으로 기록하지 않을 Exception 리스트 (기본값: empty)
ignoreException
기록하지 않을 Exception을 판단하는 Predicate<Throwable>을 설정 (커스터마이징, 기본값: throwable -> true)
recordFailure
어떠한 경우에 Failure Count를 증가시킬지 Predicate를 정의해 CircuitBreaker에 대한 Exception Handler를 재정의하는 것이다. true를 return할 경우, failure count를 증가시키게 된다 (기본값: false)
Resilience4j Retry Property
property설명
maxRetryAttempts
최대 재시도 수(최초 호출도 포함, 기본값 3)
waitDuration
재시도 할 때마다 기다리는 고정시간 (1초[1000ms], 기본값: 0.5초[500ms])
retryOnResultPredicate
반환되는 결과에 따라서 retry를 할지 말지 결정하는 filter, true로 반환하면 retry하고 false로 반환하면 retry 하지 않습니다. (기본값: (numOfAttempts,Either<throwable, result) -> waitDuration)
retryExceptionPredicate
예외(Exception)에 따라 재시도 여부를를 결정하기 위한 filter, 만약 예외에 따라 재시도해야 한다면 true를, 그 외엔 false를 리턴해야 한다. (기본값: result -> false)
retryExceptions
실패로 기록되는 블랙리스트 예외. empty일 경우 모든 에러 클래스를 재시도 한다. (기본값: empty)
ignoreExceptions
무시되어야 하는 예외(화이트리스트) 즉, 재시도 되지 않아야 할 에러 클래스 리스트이다. (기본값: empty)
failAfterMaxRetries
설정한 maxAttempts 만틈 재시도하고 나서도 결과가 여전히 retryOnResultPredicate를 통과하지 못했을 때 MaxRetriesExceededException 발생을 활성화/비활성화하는 boolean (기본값: false)
* 그외 모듈에 대한 속성값이 궁금하시다면 아래의 Resilience4j 공식 document 를 참고해주세요.
CascadeType.ALL: 모든 Cascade를 적용 CascadeType.PERSIST: 엔티티를 영속화할 때, 연관된 엔티티도 함께 유지 CascadeType.MERGE: 엔티티 상태를 병합(Merge)할 때, 연관된 엔티티도 모두 병합 CascadeType.REMOVE: 엔티티를 제거할 때, 연관된 엔티티도 모두 제거 CascadeType.DETACH: 부모 엔티티를 detach() 수행하면, 연관 엔티티도 detach()상태가 되어 변경 사항 반영 X CascadeType.REFRESH: 상위 엔티티를 새로고침(Refresh)할 때, 연관된 엔티티도 모두 새로고침
symmetric : x.equals(y) 가 참이라면 y.equals(x) 역시 참이어야 한다
transitive : x.equals(y) 가 참이고 y.equals(z) 가 참일 때 x.equals(z) 역시 참이어야 한다
consistent : x.equals(y)가 참일 때 equals 메서드에 사용된 값이 변하지 않는 이상 몇번을 호출해도 같은 결과가 나와야 한다
x가 null이 아닐 때 x.equals(null) 은 항상 거짓이어야 한다
[ JPA 에서의 equals ]
엔티티 매니저의 영속성 컨텍스트에서 1차 캐시를 이용해 같은 ID의 엔티티를 항상 같은 객체로 가져올 수 있다. 하지만 1차 캐시를 초기화 한 후 다시 데이터베이스에서 동일한 엔티티를 읽어오는 경우 초기화 전에 얻었던 객체와 초기화 이후에 얻은 객체가 서로 다른 객체로 생성된다.
이는 equals 메서드의 consistent 원칙을 위반하는 것이며 엔티티는 자바 객체라기 보단 데이터베이스 테이블 레코드에 가깝기 때문에 엔티티 객체의 필드(pk)가 동일하다면 같은 레코드, 즉 객체라고 판단해야 한다.
이와 같은 이유로 equals 메서드와 hashCode 메서드를 재정의 해야 한다.
* 준영속 상태의 엔티티 간 비교, 비교할 두 인자가 둘 다 null 인 상태에서의 비교 등을 고려하여
1. from: 하나의 매개변수를 받아서 해당 타입의 인스턴스 생성 2. of: 여러개의 매개변수를 받아서 인스턴스를 생성 3. instance or getInstance: 인스턴스를 반환하지만 동일한 인스턴스임을 보장하지 않는다. 4. create or newInstance: instance 혹은 getInstance와 같지만, 매번 새로운 인스턴스를 생성하여 반환함을 보장. 5. getType: getInstance와 같으나 생성할 클래스가 아닌 다른 클래스에 팩토리 메소드를 정의할 때 사용. (호출하는 클래스와 다른 타입의 인스턴스를 반환할때 사용)
규칙 8: 일급 콜렉션 사용 이 규칙의 적용은 간단하다. 콜렉션을 포함한 클래스는 반드시 다른 멤버 변수가 없어야 한다. 각 콜렉션은 그 자체로 포장돼 있으므로 이제 콜렉션과 관련된 동작은 근거지가 마련된셈이다. 필터가 이 새 클래스의 일부가 됨을 알 수 있다. 필터는 또한 스스로 함수 객체가 될 수 있다. 또한 새 클래스는 두 그룹을 같이 묶는다든가 그룹의 각 원소에 규칙을 적용하는 등의 동작을 처리할 수 있다. 이는 인스턴스 변수에 대한 규칙의 확실한 확장이지만 그 자체를 위해서도 중요하다. 콜렉션은 실로 매우 유용한 원시 타입이다. 많은 동작이 있지만 후임 프로그래머나 유지보수 담당자에 의미적 의도나 단초는 거의 없다. - 소트웍스 앤솔로지 객체지향 생활체조편
[ 일급콜렉션의 예 ]
// 콜렉션 사용
final List<Integer> lottoTicket = new ArrayList<>();
lottoTicket.add(4);
lottoTicket.add(11);
lottoTicket.add(15);
lottoTicket.add(21);
lottoTicket.add(33);
lottoTicket.add(45);
// 일급콜렉션 (Wrapping)
public class LottoTicket {
private final List<Integer> lottoNumbers;
public LottoTicket(List<Integer> lottoNumbers){
this.lottoNumbers = lottoNumbers;
}
}
[ 일급콜렉션을 왜 써야 하는가? ]
1. 비지니스에 종속적인 자료구조 : Wrapper 클래스(일급콜렉션 클래스) 내에서 콜렉션에 대한 유효성 검사 및 정제 등의 로직을 포함하여 비지니스에 필요한 자료구조를 만들 수 있다. (ex: LottoTicket 내에서 Lotto 번호 범위(1~45)에 대한 유효성 검사 로직을 추가)
2. 불변 : 콜렉션 변수를 final 로 선언시 재할당만 불가할 뿐, 콜렉션에 .set 등이 가능하여 불변성 보장이 되지 않는 반면 일급콜렉션 사용시 선언 후엔 조작이 불가.
3. 상태와 행위를 한 곳에서 관리 : 값과 로직이 함께 존재 (ex: 일급콜렉션 클래스 내에 콜렉션의 합계를 구하는 메소드를 구현하여 상태와 행위를 한 곳에서 관리)
4. 이름이 있는 컬렉션 : Wrapping 한 클래스를 사용하므로 인스턴스 생성시 new ArrayList<>() 대신 new LottoTicket(createNonDuplicatedNumbers()) 이 가능.
* 일급콜렉션에서 Wrapping 한 인스턴스 변수를 외부에서 필요로 할 땐?
Collections.unmidifiableList 를 사용하여 리턴하여 외부에서의 변경을 막는다.