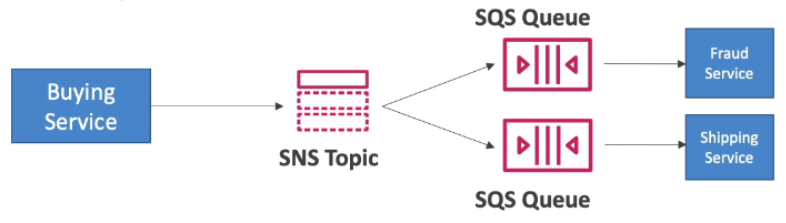
[ Kinesis ]
Apache Kafka 를 대체, 실시간 big data 관련 작업에 유리
- Kinesis is a managed alternative to Apache Kafka
- Great for application logs, metrics, Iot, clickstreams
- Great for "real-time" big data
- Grate for streaming processing frameworks (Spark, NiFi, etc...)
- Data is automatically replicated to 3AZ
Kinesis Streams : low latency streaming ingest at scale
Kinesis Analytics : perform real-time analytics on streams using SQL
Kinesis Firehose : load stream into S3, Redshift, ElasticSearch..
[ 1. Kinesis Streams ]
Shard 로 stream 이 나뉘어짐, 데이터는 default 로 하루간 보관됨, 데이터에 대한 재처리 가능, 데이터가 kinesis 에 한 번 삽입되면 지워지지 않음
- Streams are divided in ordered Shards/Partitions
- Data retention is 1 day by default, can go up to 365 days
- Ability to reprocess/replay data
- Multiple applications can consume the same stream
- Real-time processing with scale of throughput
- Once data is inserted in Kinesis, it can't be deleted (immutability)
[ Kinesis Streams Shards ]
SHARD 하나당 1 MB/s 쓰기 , 2 MB/s 읽기
SHARD 갯수 대로 과금, SHARD 갯수는 reshard(추가), merge(병합) 을 통해 증/감 가능
- One stream is made of many different shards
- 1 MB/s or 1000 messages/s at write per SHARD
- 2 MB/s at read per SHARD
- Billing is per shard provisioned, can have as many shards as you want
- Batching available or per message calls
- The number of shards can evolve over time (reshard/merge)
- Records are ordered per shard
[ AWS Kinesis API - Put records ]
partition key 를 사용할 경우 동일한 키는 동일한 파티션으로 보내짐, 처리량을 높이고싶을 경우 PutRecords 와 batching 을 사용
- PutRecord API + Partition key that gets hashed
- The same key goes to the same partition (helps with ordering for a specific key)
- Messages sent get a "sequence number"
- Choose a partition key that is highly distributed (helps prevent "hot partition")
user_id if many users
Not country_id if 90% of the users are in one country
- Use Batching with PutRecords to reduce costs and increase throughput
- ProvisionedThroughputExceeded Exception occurs if we go over the limits
[ AWS Kinesis API - Exceptions ]
ProvisionedThroughputExceeded Exceptions
- Happens when sending more data (exceeding MB/s or TPS for any shard)
- Make sure you don't have a hot shard (such as your partition key is bad and too much data goes to that partition)
* Solution : Retries with backoff / Increase shards (scaling)
[ AWS Kinesis API - Consumers ]
- Can use a normal consumer : CLI, SDK, etc...
- Can use Kinesis Client Library (in Java, Node, Python, Ruby, .NET)
: KCL uses DynamoDB to checkpoint offsets
: KCL uses DynamoDB to track other workers and share the work amongst shards
[ Kinesis Security ]
Control access / authorization using IAM policies
Encryption in flight using HTTPS endpoints
Encryption at rest using KMS
Possibility to encrypt/decrypt data client side(harder)
VPC Endpoints available for Kinesis to access within VPC
[ 2. Kinesis Data Firehose ]
서버리스, 자동 스케일링, 관리가 필요없음
실시간에 가까움(실시간이 아님)
- Fully Managed Service, no administration, automatic scaling, serverless
- Load data into Redshift/Amazon S3/ElasticSearch/Splunk
- Near Real Time
60 seconds latency minimum for non full batches
Or minium 32 MB of data at a time
- Supports many data formats, conversions, trasformations, compression
- Pay for the amount of data going through Firehose
[ Kinesis Data Streams vs Firehose ]
# Streams
- Going to write custom code (producer/consumer)
- Real time(~200ms)
- Must manage scaling(shard splitting/merging)
- Data Storage for 1 to 7 days, replay capability, multi consumers
# Firehose
- Fully managed, send to S3, Splunk, Redshift, ElasticSearch
- Serverless data transformations with Lambda
- Near real time (lowest buffer time is 1 minute)
- Automated Scaling
- No data storage
[ Kinesis Data Analytics ]
- Perform real-time analytics on Kinesis Streams using SQL
- Kinesis Data Analytics :
Auto Scaling
Managed : no servers to provision
Continuous : real time
- Pay for actual consumption rate
- Can create streams out of the real-time queries
[ Data ordering for Kinesis vs SQS FIFO ]
각각의 객체의 순서를 지키며 데이터를 사용하고자 할 경우 객체별 partition key 를 사용, 키는 항상 동일한 shard 로 보내짐
to consume the data in order for each object, send using a "partition key" value of the "object_id"
the same key will always go to the same shard
[ Ordering data into SQS ]
SQS Standard 는 순차 처리가 아님. FIFO를 사용하며 다수의 consumer가 존재할 경우 GROUP ID 를 사용하여 메시지를 그루핑 할 수 있음 (Kinesis 의 partition key 와 비슷)
# Standard Case
- For SQS standard, there is no ordering
- For SQS FIFO, if you don't use a Group ID, messages are consumed in the order they are sent, with only one consumer
# When to use Group ID
- You want to sacle the number of consumers, but you want messages to be "grouped" when they are related to each other
- Then you use a Group ID (similar to Partition key in Kinesis)
[ # Kinesis vs SQS ordering ]
Let's assume 100 trucks, 5 kinesis shards, 1 SQS FIFO
# Kinesis Data Streams :
- On average you will have 20 trucks per shard
- Trucks will have their data ordered within each shard
- The maximum amount of consumers in parallel we can have is 5
- Can receive up to 5 MB/s of data
# SQS FIFO :
- you only have one SQS FIFO queue
- you will have 100 Group ID
- You can have up to 100 consumers (due to the 100 Group ID)
- You have up to 300 messages per second (or 3000 if using batching)