[3강. 데이터링크 계층 프로토콜의 HDLC 2]
- frame은 헤더의 시퀀스 넘버를 사용하여 순서를 구분
# ACK 와 NAK
ACK : 정상 수신
NAK : 비정상 수신
[ARQ의 종류]
1. Stop N Wait ARQ
프레임을 보내고 ACK/NAK 올때까지 다음 프레임을 보내지 않음
송신측은 time out 이 나면 재전송
(송신측 sliding window 가 1인 Go-Back-N ARQ와 같다)
# piggybacking
ACK와 데이터를 동시에 보냄
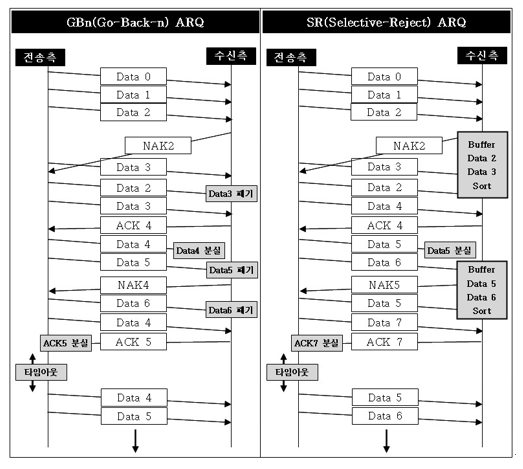
2. Go-Back-n ARQ (GBn ARQ)
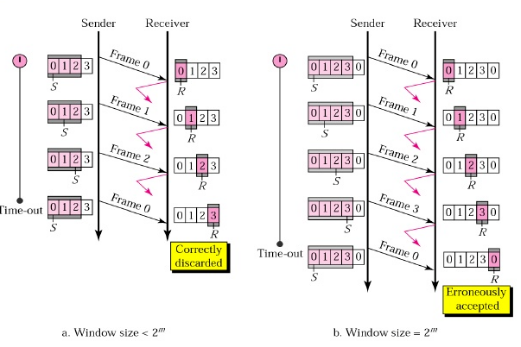
window 크기 : 2의 (m-1)제곱 만큼 (window 크기만큼 수신측 회신 없이 프레임 전송)
항상 순서대로 ACK 를 받아서 처리
손상 분실된 프레임 이후의 프레임 모두 재전송(효율 낮음)
구조 간단 하고 구현 단순
수신측 데이터 문제있을 경우 NAK 전송 혹은 silence
타이머 만료시 ACK 오지 않은 프레임(sliding window의 첫 프레임)부터 재전송
수신측 sliding window 크기는 1로 받고자 하는 프레임의 번호만 가리키고 있다. 수신된 프레임의 번호가 기다리는 프레임의 번호가 아닌 경우 버리고 간다.(silence)
3. Selective Repeat ARQ (SR ARQ)
Go-Back-n ARQ 비효율 문제 개선한 방식.
손상되거나 분실된 프레임만 재전송(NAK 받은 프레임)
데이터 재정렬이 필요, 별도 버퍼 필요
Timer는 각 프레임에 존재하여 각 타이머 만료시 해당 프레임을 다시 보냄.
ACK3이 오면 프레임 2만 잘 받았다고 판단
[HDLC (High level Data Link Control) 프로토콜]
- ISO에서 개발한 국제 표준 프로토콜.
- 점대점링크(point to point), 멀티포인트 링크에서 사용
- 오류제어를 위해 GBn ARQ, SR ARQ 방식 사용
1. 분류 정의
Data link 프로토콜의 종류 : Asynchronous/Synchronous protocols
Asynchronous protocols의 종류 : XMODEM, YMODEM, ZMODEM, BLAST...
Synchronous protocols의 종류 : Character-oriented protocols, Bit-oriented protocols
Bit-oriented protocols 의 종류 : SDLC, HDLC...
2. HDLC 의 3가지 station types
1) primary station(master): link 컨트롤에 책임을 가짐
2) secondary station(slave): master에 의해 제어당하는 station
3) combined station: primary/secondary 의 조합
3. Unbalanced(1:N Multi-drop(ex:전화선))/Balanced(1:1 peer to peer) 형태의 link 모두 지원
4. half-duplex(반이중: 전송 수신 동시에 불가 (ex: Stop N Wait ARQ))/full-duplex(전이중: 전송 수신 동시 가능 (ex: GBn ARQ)) 모두 지원
5. NRM(normal response mode), ARM(asynchronous response mode), ABM(asynchronous balanced mode) 지원
1) NRM: primary 의 command 에 의해 secondary가 데이터 전송 가능
2) ARM: secondary가 primary에 언제든지 데이터 전송 가능(주종 관계는 NRM과 동일)
3) ABM: primary, secondary 관계가 동등 (주로 쓰임)
6. Frame 형태
1) I-frames(Information frames) : 일반적인 정보가 담긴 데이터(seq 존재)
2) S-frames(Supervisory frames) : ACK, NAK...
3) Unnumbered frames(U-frames) : seq가 없는 데이터(ex: 연결/단절 신호)

7. Frame 형태 - 상세
1) Flag: 1byte
2) Address: 1byte
3) Control field: 1byte
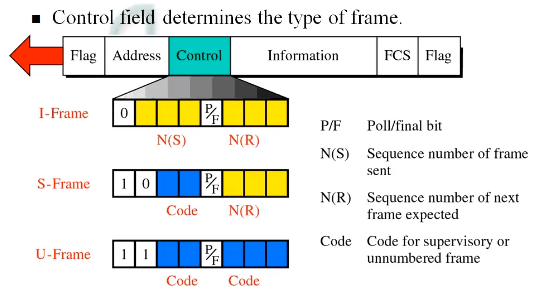
* S-Frame
REJ : GBn ARQ 에서의 NAK (NAK3 : 3이후로 전부 재전송)
SREJ : SR ARQ 에서의 NAK (NAK3 : 3만 재전송)

* U-Frame
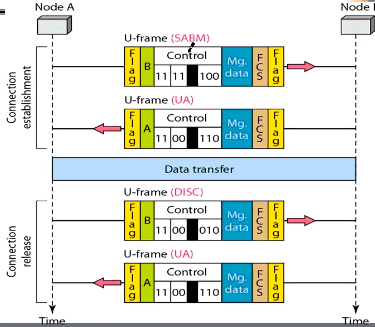
4) data: N bytes
5) FCS: 2Bytes (데이터 에러 검출용)
[PPP (Point to Point Protocol구성요소]
1. LCP (Link Control Protocol)
데이터는 없고 링크를 관리하기 위한 프로토콜
2. Authentication protocols
1) PAP : 유저가 id, pw 송신, 시스템은 ACK/NAK 회신 (보안취약)

2) CHAP : 시스템은 challenge value 를 보내고 유저는 pw 에 challenge value를 더한 값을 송신.
시스템은 그 값을 확인하여 인증처리. (pw가 노출되지 않아 보안성 높음)
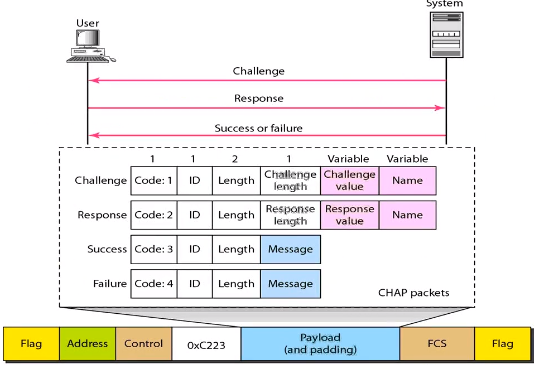
3. NCP (Network control protocols)
LCP -> PAP/CHAP -> NCP -> 데이터 송신 -> NCP -> LCP 와 같은 순서

※ KOCW 성균관대학교 안성진 교수님의 컴퓨터네트워크 강의 참고
'Computer Science > data comm & network' 카테고리의 다른 글
| [Network] 컴퓨터 네트워크 10~12 : 유선 LAN, Fast/Gigabit/10-G Ethernet, 802.3 (0) | 2021.01.17 |
|---|---|
| [Network] 컴퓨터네트워크 7~9 : Multiple-access protocols(Random access/Controlled-access/Channelization protocols) (0) | 2021.01.14 |
| [Network] 컴퓨터네트워크 1~2 : Data link, HDLC, Frame (0) | 2021.01.05 |
| [Network] 4. P2P : BitTorrent, tit-for-tat (0) | 2020.04.13 |
| [Network] 3. Application layer : DNS, TTL (0) | 2020.04.06 |