프로세스
실행중인 프로그램을 프로세스라 한다
프로세스의 문맥(context)
특정 시점에서 프로세스가 어디까지 실행됐는지를 파악하기 위해

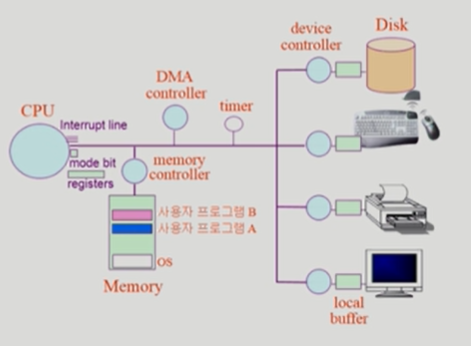
- CPU 수행 상태를 나타내는 하드웨어 문맥
Program counter
각종 register
- 프로세스의 주소 공간
code, data, stack
- 프로세스 관련 커널 자료 구조
PCB(Process Control Block)
Kernel stack
프로세스의 상태
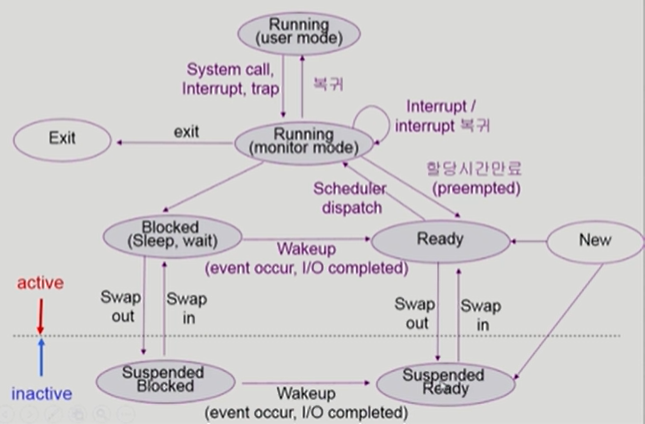
Running : CPU를 잡고 인스트럭션(instruction)을 수행중인 상태
Ready : CPU를 기다리는 상태(메모리 등 다른 조건을 모두 만족하는 상태)
Blocked (wait, sleep) :
- CPU를 주어도 당장 instruction을 수행할 수 없는 상태
- process 자신이 요청한 event(ex: I/O)가 즉시 만족되지 않아 이를 기다리는 상태
ex) 디스크에서 file을 읽어와야 하는 경우
Suspended (stopped) :
- 외부적인 이유로 프로세스의 수행이 정지된 상태
- 프로세스는 통째로 디스크에 swap out 된다
ex) 사용자가 프로그램을 일시 정지 시킨 경우,
메모리에 너무 많은 프로세스가 올라와 있을 때(Medium-term Scheduler에 의해)
New : 프로세스가 생성 중인 상태 (보통 프로세스의 상태로 포함되지 않음)
Terminated : 수행이 끝난 상태 (보통 프로세스의 상태로 포함되지 않음)
※ Blocked 와 Suspended 의 차이
Running, Ready, Blocked 모두 CPU 관점에서의 상태 분류일 뿐 실제로 프로세스의 작업이 수행이 되고 있는 상태 (CPU에서 프로세스 수행중(Running), I/O에서 프로세스 수행중(Blocked)), 반면 Suspended 는 프로세스 수행 자체가 외부에 의해 정지된 상태
Blocked : Blocked 자신이 요청한 event가 만족되면 Ready
Suspended : 외부에서 resume 해주어야 Active
프로세스 상태의 흐름
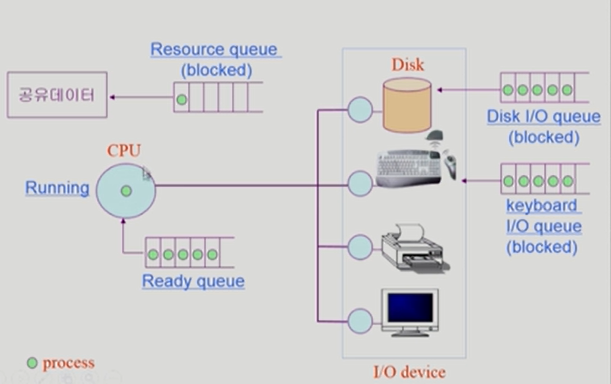
1. CPU에서 하나의 프로세스를 처리 중 (Running)
2. 타이머 인터럽트가 들어오며 프로세스가 Ready Queue 맨 뒤로 가서 줄을 서게 됨 (Ready)
(실제론 Queue 순서가 아닌, 우선순위에 의해 실행함)
3. 다음 프로세스를 처리
4. I/O 입력이 요구되어 프로세스의 상태가 blocked 로 바뀌고 키보드 I/O Queue 로 이동하여 줄을 서게 됨 (Blocked)
5. 입력이 완료되면 device controller 가 인터럽트를 걸어 CPU 에게 알림
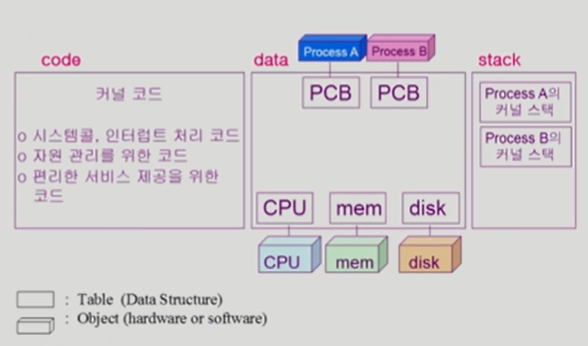
PCB(Process Control Block)
운영체제가 각 프로세스를 관리하기 위해 프로세스당 유지하는 정보
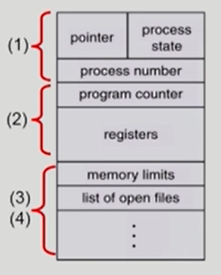
1) OS가 관리상 사용하는 정보
Process state, Process ID, Priority, Scheduling information
2) CPU 수행 관련 하드웨어 값
Program Counter, registers
3) 메모리 관련
Code, Data, Stack 위치정보
4) 파일 관련
Open File Descriptors
문맥 교환(Context Switch)
CPU를 한 프로세스에서 다른 프로세스로 넘겨주는 과정

1) CPU를 내어주는 프로세스 상태를 그 프로세스의 PCB에 저장
2) CPU를 새롭게 얻는 프로세스의 상태를 PCB에서 읽어옴

a) 프로세스 A --> 인터럽트 or 시스템콜 --> 커널 --> 프로세스 A : 문맥교환 X
b) 프로세스 A --> 인터럽트 or 시스템콜 --> 커널 --> 프로세스 B : 문맥교환 O
a의 경우에도 CPU 수행 정보 등 context 일부를 PCB에 저장해야 하지만 문맥교환을 하는 b의 경우가 오버헤드가 훨씬 더 크다. (b의 경우 cache memory flush 가 수행됨)
프로세스 큐의 종류
1) Job Queue : 현재 시스템 내에 있는 모든 프로세스의 집합 (Ready Queue + Device Queues)
2) Ready Queue : 현재 메모리 내에 있으면서 CPU를 잡아서 실행되기를 기다리는 프로세스 집합 (Device Queue와 베타관계)
3) Device Queues : I/O device 의 처리를 기다리는 프로세스 집합 (Ready Queue와 베타적 관계)
스케쥴러 (Scheduler)
1) Long-term Scheduler (장기 스케쥴러/Job scheduler)
- 시작 프로세스 중 어떤 것들을 ready queue로 보낼지 결정(new -> ready 로 갈 프로세스를 결정)
- 프로세스에 memory를 주는 문제
- 메모리에 올라갈 프로세스 수를 제어 (메모리에 프로그램이 너무 적거나 많으면 효율/성능이 좋지 않음)
- Time sharing system 에서는 보통 장기 스케쥴러가 없다 (무조건 ready 상태로.. (무조건 메모리에 올라감))
2) Short-term Scheduler (단기 스케쥴러/CPU scheduler)
- 어떤 프로세스를 다음번에 running 시킬지 결정
- 프로세스에 CPU를 주는 문제
- millisecond 단위로 매우 빨라야 함
3) Medium-term Scheduler (중기스케쥴러/Swapper)
- 메모리 여유 공간 마련을 위해 프로세스를 통째로 디스크로 쫓아냄
- 프로세스에게서 memory를 뺏는 문제
※ 이화여대 반효경 교수님의 운영체제 강의내용 정리
'Computer Science > OS' 카테고리의 다른 글
| [OS] 운영체제 6. CPU Scheduling : CPU 성능척도, 스케쥴링 방법(FCFS, SJF, Priority Scheduling, Round Robin) (0) | 2020.02.04 |
|---|---|
| [OS] 운영체제 5. Process Management : 프로세스 생성/종료 (0) | 2020.02.01 |
| [OS] 운영체제 4. Thread : 스레드 정의, 효과 및 장점 (0) | 2020.01.27 |
| [OS] 운영체제 2. System Structure & Program Execution : 시스템구조, 입출력 (0) | 2020.01.24 |
| [OS] 운영체제 1. OS (0) | 2020.01.19 |