1. Contiguous allocation (연속 할당)
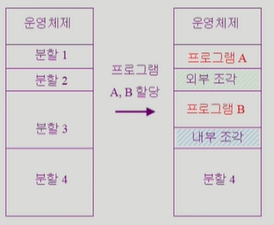
1-1) 고정분할
1-2) 가변분할
2. Noncontiguous allocation (불연속 할당)
1) Paging 기법
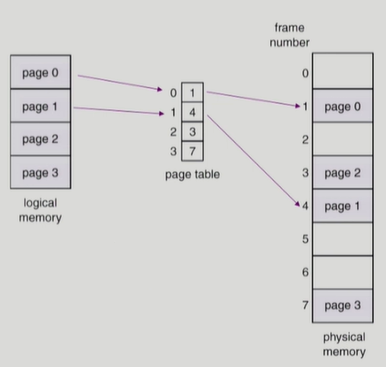
- Page table은 main memory 에 상주
- Page-table base register(PTBR)가 page table을 가리킴
- Page-table length register(PTLR)가 테이블 크기를 보관
- 모든 메모리 접근 연산에는 2번의 memory access 필요
- page table 접근 1번, 실제 data/instruction 접근 1번
- 속도 향상을 위해 자주 사용되는 주소값을 가지고 캐시와 같이 가지고 있는 TLB 사용
※ TLB

- TLB 조회시 fullscan이 이루어지므로, parellel search 가 가능한 associative registers 사용
- 주소값이 없으면(miss) page table 사용
- TLB는 context switch 시 flush 된다(process 마다 달라져야 하므로)
※ Two-Level Page Table : 2단계 페이지 테이블
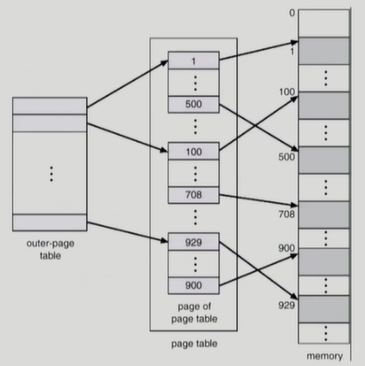
32 bit address 사용시 2^32 (4G) 의 주소 공간
page size 가 4K 일 경우 1M개의 page(=page table entry) 가 필요 ( 4G / 4K = 1M )
각 page entry가 4B 일 경우 프로세스당 4M의 page table 필요 (프로세스 하나에 page table 1개)
사용되지 않는 주소 공간에 대한 outer page table 의 엔트리 값은 NULL (대응하는 inner page table 이 없음)
inner page table의 크기는 page 크기와 동일. inner page table 은 page 내에 존재
page 하나는 4KB(inner page table도 마찬가지), entry 1개는 4Byte entry 는 총 1K 개


page offset : 4KB(페이지크기) = 2^12
P2 : page entry 갯수 1K = 2^10
P1은 outer pager table 의 index
P2는 outer page table의 page에서의 변위(displacement)
※ Multi-Level Paging : 멀티 레벨 페이징
- Address space가 커지면 다단계 페이지 테이블 필요
- 각 단계의 페이지 테이블이 메모리에 존재하므로 logical address의 physical address변환에 더 많은 메모리 접근 필요
- TLB를 통해 메모리 접근 시간을 줄일 수 있음
Memory Protection
Page table의 각 entry 마다 아래의 bit를 둔다
1) Protection bit
: page에 대한 read/write/read-only 권한
ex) code영역은 read-only, data 및 stack 영역은 read/write
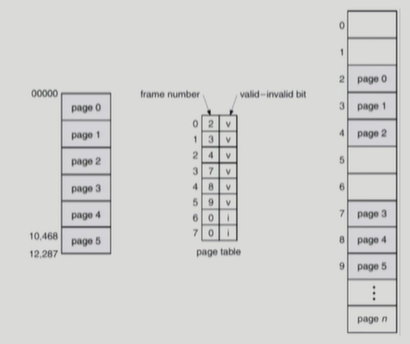
2) Valid-invalid bit (아래 그림 참고)
: valid는 해당 주소의 frame에 그 프로세스를 구성하는 유효한 내용이 있음을 뜻함(접근 허용)
: invalid는 해당 주소의 frame에 유효한 내용이 없음을 뜻함
(프로세스가 그 주소 부분을 사용하지 않거나 해당 페이지가 메모리에 올라와 있지 않고 swap area에 있는 경우)
Inverted Page Table
- Page frame 하나당 page table에 하나의 entry 를 둔 것(system-wide:시스템에 하나만 존재)
- 각 page table entry는 각각의 물리적 메모리의 page frame이 담고 있는 내용 표시(process-id, process의 logical address)
- 물리주소로 논리주소를 역으로 찾아야 하기 때문에(value 기준으로 key를 찾아야) 검색에 overhead가 큼(associative register 사용하여 해당 문제 해소)
- 기존의 테이블 페이지 구조와 정반대의 구조
1) 페이지 테이블 : 프로세스 페이지 번호를 기준으로 page table에서 logical address를 physical address 로 변환(정방향)
2) inverted 페이지 테이블 : page table의 entry에 physical memory 에 들어있는 logical address 주소가 들어 있음(역방향)
- 모든 process 별로 그 logical address에 대응하는 모든 page에 대해 page table entry가 존재(배열과 비슷한 구조), 대응하는 page가 메모리에 있든 아니든 간에 page table에는 entry로 존재와 같은 page table 의 문제점을 inverted page table은 갖지 않음.

Shared Page
- Re-entrant Code(=Pure code) : 재진입가능한 코드
- read-only로 하여 프로세스 간 하나의 code만 메모리에 올린다
- Shared code는 모든 프로세스의 logical address space에서 동일한 위치에 있어야 한다
Private code and data
- 각 프로세스들은 독자적으로 메모리에 올림
- private data는 logical address space의 아무곳에 와도 무방

2) Segmentation Architecture
- Logical address 는 segment-number(s), offset(d) 으로 구성
- 각각의 segment table 은 limit(segment의 길이), base(segment 의 시작 물리 주소) 를 가짐
- Segment-table base register(STBR) : 물리적 메모리에서의 segment table 위치
- Segment-table length register(STLR) : 프로그램이 사용하는 segment의 수

if (s > STLR) trap
if (limit < d) trap
장점 : segment 는 의미 단위이기 때문에 Sharing과 protection에 있어 paging 보다 훨씬 효과적
단점 : segment의 길이가 동일하지 않으므로 가변분할 방식에서와 동일한 문제점들이 발생
※ 이화여대 반효경 교수님의 운영체제 강의 정리