[ Docker ]
- Docker is a software development platform to deploy apps
- Apps are packaged in containers that can be run on any OS
- Apps run the same, regardless of where they're run
1) Any machine
2) No compatibility issues
3) Predictable behavior
4) Less work
5) Easier to maintain and deploy
6) Works with any language, any OS, any technology
# Where are Docker images stored?
- Docker images are stored in Docker Repositories
- Public : Docker Hub (https://hub.docker.com) or Amazon ECR Public
- Find base images for many technologies or OS
ex) Ubuntu, MySQL, NodeJS, Java
- Private : Amazon ECR (Elastic Container Registry)
[ Docker vs VM (Virtual Machines) ]
- Docker is "sort of" a virtualization technology, but not exactly
- Resources are shared with the host > many containers on one server

[ Docker Containers Management ]
To manage containers, we need a container management platform
1) ECS : Amazon's own container platform
2) Fargate : Amazon's own Serverless container platform
3) EKS : Amazon's managed Kubernetes
1. ECS
- ECS = Elastic Container Service
- Launch Docker containers on AWS
- You must provision & maintain the infrastructure(the EC2 instances)
- AWS takes care of starting/stopping containers
- Has integrations with the Application Load Balancer
2. Fargate
- Launch Docker containers on AWS
- You do not provision the infrastructure (no EC2 instances to manage) - simpler
- Serverless offering
- AWS just runs containers for you based on the CPU/RAM you need
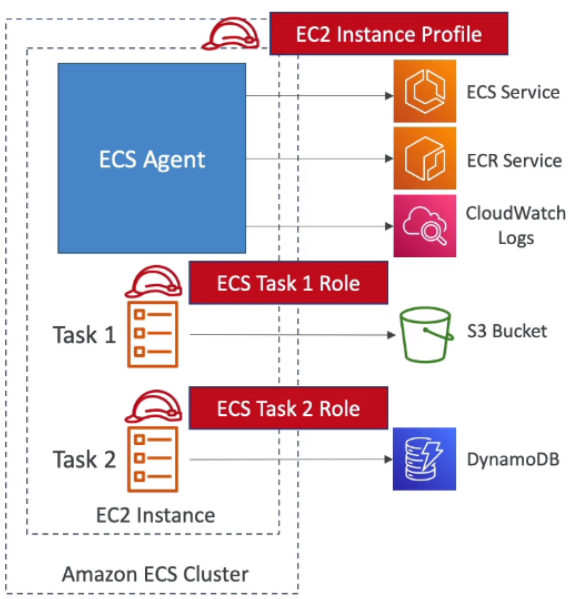
# IAM Roles for EC2 Tasks
1) EC2 Instance Profile :
- Used by the ECS agent
- Makes API calls to ECS service
- Send container logs to CloudWatch Logs
- Pull Docker image from ECR
- Reference sensitive data in Secrets Manager or SSM Parameter Store
2) ECS Task Role :
- Allow each task to have a specific role
- Use different roles for the different ECS Services you run
- Task Role is defined in the task definition
# ECS Data Volumes - EFS File Systems
- Works for both EC2 Tasks and Fargate tasks
- Ability to mount EFS volumes onto tasks
- Tasks launched in any AZ will be able to share the same data in the EFS volume
- Fargate + EFS = serverless + data storage without managing servers
- Use case : persistent multi-AZ shared storage for you containers
[ Load Balancing ]
[ 1. Load Balancing for EC2 Launch Type ]
- We get a dynamic port mapping
- The ALB supports finding the right port on your EC2 Instances
- You must allow on the EC2 instance's security group any port from the ALB security group

[ 2. Load Balancing for Fargate ]
- Each task has a unique IP
- You must allow on the ENI's security group the task port from the ALB security group

[ ECS Scaling ]
1. Service CPU Usage

2. SQS Queue

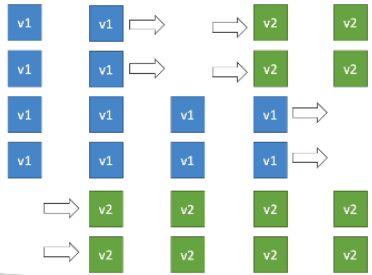
[ ECS Rolling Updates ]
When updating from v1 to v2, we can control how many tasks can be started and stopped, and in which order
- can set minimum/maximum healthy percent
Example 1 : Min 50% / Max 100%

Example 2 : Min 100% / Max 150%
[ Amazon ECR : Elastic Container Registry ]
- Store, manage and deploy containers on AWS, pay for what you use
- Fully integrated with ECS & IAM for security, backed by Amazon S3
- Supports image vulnerability scanning, version, tag, image lifecycle

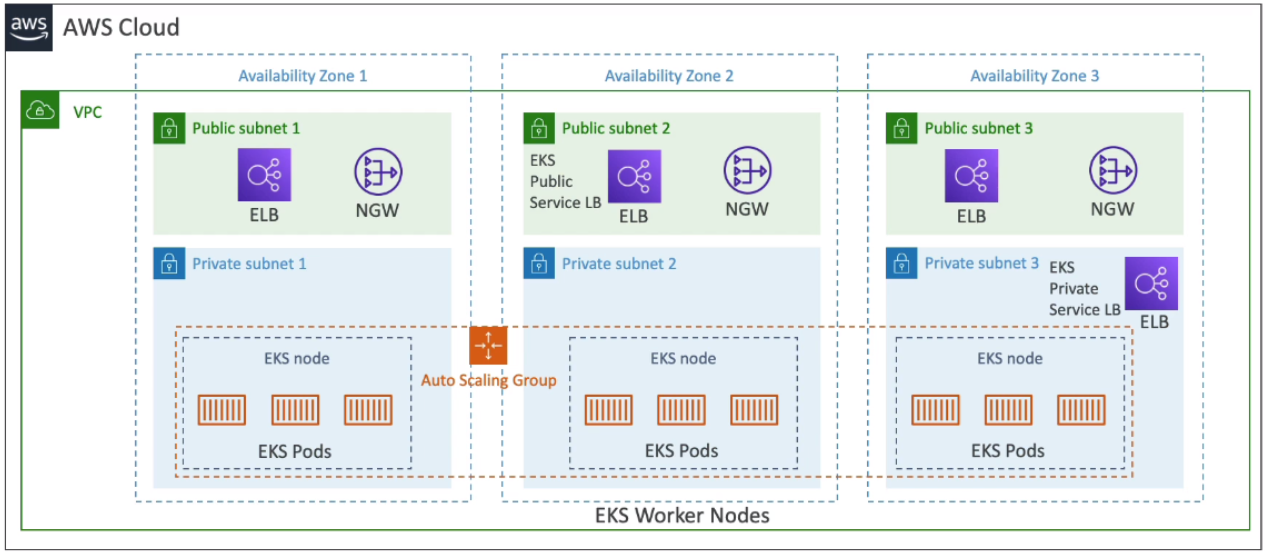
[ Amazon EKS Overview ]
Amazon EKS = Amazon Elastic Kubernetes Service
- It is a way to launch managed Kubernetes clusters on AWS
- Kubernetes is an open-source system for automatic deployment, scaling and management of containerized (usually Docker) application
- It's a alternative to ECS, similar goal but different API
- EKS supports EC2 if you want to deploy worker nodes or Fargate to deploy serverless containers
Use case: if your company is already using Kubernetes on-premises or in another cloud, and wants to migrate to AWS using Kubernetes
- Kubernetes is cloud-agnostic (can be used in any cloud-Azure, GCP...)
'infra & cloud > AWS' 카테고리의 다른 글
| [AWS] 14-2. Lambda@Edge (0) | 2021.09.02 |
|---|---|
| [AWS] 14. Serverless : Lambda (0) | 2021.09.01 |
| [AWS] 12-4. Amazon MQ, SQS vs SNS vs Kinesis (0) | 2021.04.25 |
| [AWS] 12-3. Kinesis Data Streams (0) | 2021.04.18 |
| [AWS] 12-2. Decoupling application: SNS, SNS+SQS (Fan Out) (0) | 2021.04.14 |